pymllm Runtime Design¶
总览¶
pymllm 是 mllm 的 Python serving runtime。它不是 mllm 的 C++ Backend,而是一套
围绕 PyTorch / CUDA 生态搭起来的在线推理服务运行时,目标设备是 Jetson Orin 这类边缘
GPU,重点支持 Qwen3、Qwen3-VL、Qwen3.5 系列。
它的分层借鉴了 SGLang serving runtime,但做了明显收缩:主路径只盯单机单 GPU,优先保证 在 Jetson 上跑得起来、调得动、改得动,而不是去覆盖大规模分布式 serving 的全部复杂度。
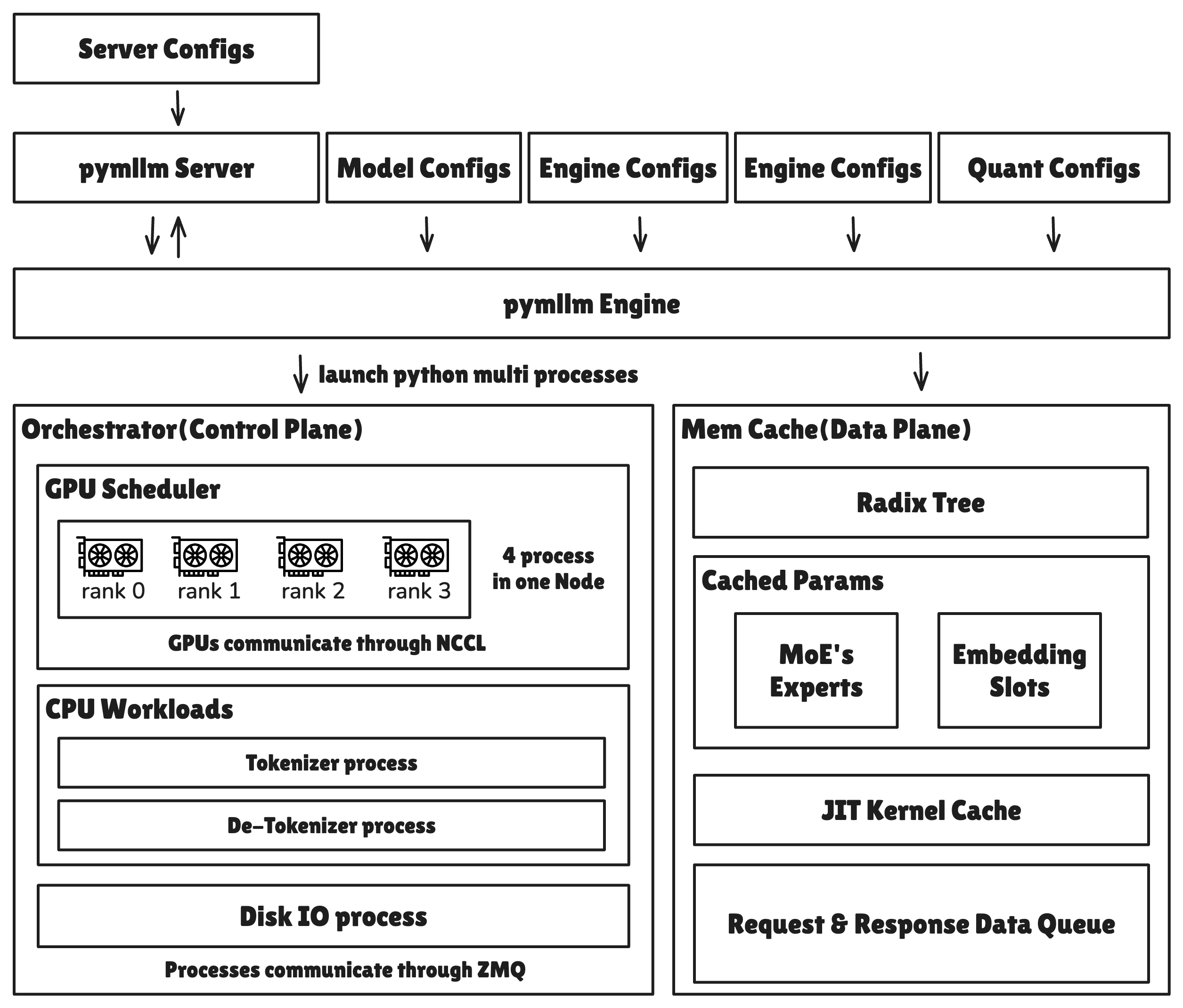
Figure 1: pymllm runtime architecture.¶
整体分层¶
从开发者视角看,pymllm 大致分五层:
服务入口层:FastAPI HTTP server,提供 OpenAI-compatible API 和原生
/generateAPI。配置层:
ServerConfig、ModelConfig、QuantizationConfig统一解析模型 路径、dtype、调度参数、缓存参数、量化参数和各类加速开关。控制面:
Engine拉起 tokenizer、scheduler、detokenizer 子进程,主进程里维护 request/response 状态。数据面:scheduler 持有 GPU 的
ModelRunnerProcess,负责 batch 构造、KV cache 分配、prefix cache 命中、forward 和 sampling。加速层:FlashInfer、CUDA Graph、Triton、CUTLASS 和
mllm-kernel提供 attention、 量化、GEMM、缓存写入这些高频算子。
进程拓扑¶
Engine 启动时创建三个子进程,request/response 的管理逻辑留在主进程:
Main Process
├── FastAPI Server
├── Engine
└── RequestResponseProcess
│
│ ZMQ
▼
TokenizerProcess
│
│ ZMQ or shared queue
▼
SchedulerProcess
└── ModelRunnerProcess (in-process, owns GPU resources)
│
│ ZMQ
▼
DetokenizerProcess
│
│ ZMQ
▼
RequestResponseProcess
这里最关键的一个取舍是:GPU 资源由 scheduler 进程内的 ModelRunnerProcess 直接持有。
这样调度、KV cache 释放、prefix cache 更新和模型 forward 都在同一个进程里完成,省掉了
model worker 进程之间同步 GPU 资源的那套复杂度。
请求生命周期¶
一次 chat completion 请求的典型路径:
HTTP server 收到请求,转成
GenerateReqInput。RequestResponseProcess分配 request id,把请求送进 tokenizer。TokenizerProcess调 tokenizer / processor,产出TokenizedGenerateReqInput。SchedulerProcess接到 tokenized request,创建Req,放进等待队列。scheduler 按 token budget、running request 数和 prefill/decode 状态构造
ScheduleBatch。ModelRunnerProcess为 batch 分配 request slot 和 KV slot,做 prefix matching。ModelRunner构造ForwardBatch,初始化 attention backend metadata,调模型forward,再对 logits 做 sampling。scheduler 更新每个
Req的输出 token、finished reason 和 timing 字段。DetokenizerProcess把 token id 转回文本。HTTP server 以普通 JSON 或 SSE streaming 返回。
控制面:Engine 与配置¶
pymllm.configs.server_config.ServerConfig 是服务运行时的主配置对象,覆盖几类参数:
模型与 tokenizer:
model_path、tokenizer_path、load_format、dtype。HTTP server:
host、port、api_key、served_model_name。调度与内存:
max_running_requests、max_total_tokens、max_prefill_tokens、mem_fraction_static。加速后端:
attention_backend、gdn_decode_backend、disable_cuda_graph、enable_torch_compile。IPC 与多模态传输:
enable_shared_queue、tensor_transport_mode、cuda_ipc_pool_size_mb。观测与调试:
log_level、decode_log_interval。
Engine 启动前会先加载 HuggingFace config,解析 EOS token、默认输出长度和 dtype,并
确认 model / tokenizer 路径可用。启动之后它会盯着子进程的健康状态,任何一个核心子进程异常
退出,整个服务都会被标记为 unhealthy。
调度器¶
SchedulerProcess 是 pymllm 的中心调度组件,干这几件事:
接收 tokenized request。
把输入请求转成内部
Req状态。按 prefill / decode 状态构造
ScheduleBatch。守住
max_running_requests、max_total_tokens、max_prefill_tokens这些资源约束。请求结束或中止时释放 request slot 和 KV slot。
把 decode token 发给 detokenizer。
当前调度策略以 FCFS 加单 GPU 资源约束为主。max_prefill_tokens 用来限制一轮调度能接纳的
prefill token 数;长 prompt 的运行时 chunked prefill 切分还没接进来,是后续的事。
ModelRunner¶
ModelRunner 是真正跑模型 forward 的组件。初始化阶段它会:
设置 CUDA device 和默认 dtype。
加载模型类和 safetensors 权重。
解析模型 metadata,比如 layer 数、head 数、head dim、context length。
初始化 request-to-token pool、token-to-KV pool 和 KV allocator。
初始化 attention backend。
预热 cuBLAS。
按配置 capture decode CUDA Graph。
forward 分 extend 和 decode 两类:
extend / prefill:处理 prompt token,写 KV cache,返回每个请求最后一个 token 的 logits。
decode:每个请求生成一个新 token,复用已有 KV cache 和 attention metadata。
KV cache 与 prefix cache¶
pymllm.mem_cache.memory_pool 里的 KV 管理是三层结构:
ReqToTokenPool
(request slot, position) -> kv index
TokenToKVPoolAllocator
管理空闲的整数 KV slot
KVPool
在 GPU 上存每层的 K/V tensor
TokenToKVPoolAllocator 用 free-list 管理 KV slot,并提供批量释放接口,在大量请求结束或
prefix cache eviction 时降低开销。KVPool 在条件满足时调用 mllm-kernel 的
store_cache JIT kernel 写 K/V,否则回退到 PyTorch indexing。
prefix cache 目前有三种实现:
RadixCache:标准的 radix-tree prefix cache。ChunkCache:关掉 radix cache 时用的简单缓存路径。MambaRadixCache:给带 GDN / Mamba-like 状态的 hybrid 模型预留的状态缓存路径。
开 RadixCache 时,extend batch 会先做 prefix matching:命中的 prefix token 不再重复计算,
但对应的 radix tree 节点会被 lock 住,直到请求结束或资源释放才 unlock。
IPC 与多模态数据传输¶
普通控制消息走 ZMQ。多模态请求里的大 tensor 可以走 shared queue 这条 fast path,由
enable_shared_queue 和 tensor_transport_mode 控制。
tensor_transport_mode 有三种模式:
模式 |
行为 |
适用场景 |
|---|---|---|
|
GPU tensor 先拷回 CPU,再放进 POSIX shared memory。 |
最稳妥,调试优先。 |
|
GPU tensor 通过 CUDA IPC handle 跨进程共享。 |
省掉 GPU→CPU 拷贝,但长时间服务里可能踩到 PyTorch IPC 的生命周期问题。 |
|
用预分配的 GPU workspace,发送方回收 chunk。 |
面向生产服务推荐的 GPU tensor 传输方式。 |
与 mllm C++ Backend 的关系¶
pymllm 和 cpu_backend、qnn_backend、ascend_backend 不在同一个层级:
C++ Backend 接的是 mllm C++ 那套 Tensor、Op、Module、Dispatcher 和设备 allocator。
pymllm接的是 Python / PyTorch serving pipeline,服务在线推理、模型加载、KV cache、 调度和 CUDA kernel 集成。mllm-kernel是两边都可以借鉴的低层 kernel 工具包,不过目前pymllm更直接依赖其中 的 Python JIT CUDA kernel。